Vous avez la possibilité de visualiser les Wait Events dans PoWA 3.2.0 grâce à l’extension pg_wait_sampling extension.
Wait Events & pg_wait_sampling
Les wait events sont une fonctionnalité connues, et bien utiles, dans de
nombreux moteurs de base de données relationnelles. Ceux-ci ont été ajouté à
PostgreSQL 9.6, il
y a maintenant quelques versions. Contrairement à la plupart des autres
statistiques exposées par PostgreSQL, ceux-ci ne sont qu’une vision à un
instant donné des événements sur lesquels les processus sont en attente, et non
pas des compteurs cumulés. Vous pouvez consulter cette information en
utilisant la vue pg_stat_activity, par exemple :
=# SELECT datid, pid, wait_event_type, wait_event, query FROM pg_stat_activity;
datid | pid | wait_event_type | wait_event | query
--------+-------+-----------------+---------------------+-------------------------------------------------------------------------
<NULL> | 13782 | Activity | AutoVacuumMain |
16384 | 16615 | Lock | relation | SELECT * FROM t1;
16384 | 16621 | Client | ClientRead | LOCK TABLE t1;
847842 | 16763 | LWLock | WALWriteLock | END;
847842 | 16764 | Lock | transactionid | UPDATE pgbench_branches SET bbalance = bbalance + 1229 WHERE bid = 1;
847842 | 16766 | LWLock | WALWriteLock | END;
847842 | 16767 | Lock | transactionid | UPDATE pgbench_tellers SET tbalance = tbalance + 3383 WHERE tid = 86;
847842 | 16769 | Lock | transactionid | UPDATE pgbench_branches SET bbalance = bbalance + -3786 WHERE bid = 10;
[...]Dans cet exemple, nous voyons que le //wait event// pour le pid 16615 est un
Lock sur une Relation. En d’autre terme, la requête est bloquée en
attente d’un verrou lourd, alors que le pid 16621, qui clairement détient le
verrou, est inactif en attente de commandes du client. Il s’agit
d’informations qu’il était déjà possible d’obtenir avec les anciennes versions,
bien que cela se faisait d’une autre manière. Mais plus intéressant, nous
pouvons également voir que le //wait event// pour le pid 16766 est un
LWLock, c’est-à-dire un Lightweight Lock, ou verrou léger. Les verrous
légers sont des verrous internes et transitoires qu’il était auparavant
impossible de voir au niveau SQL. dans cet exemple, la requête est en attente
d’un WALWriteLock, un verrou léger principalement utilisé pour contrôler
l’écriture dans les tampons des journaux de transaction. Une liste complète
des //wait events// disponible est disponible sur la documentation
officielle.
Ces informations manquaient curellement et sont bien utiles pour diagnostiquer
les causes de ralentissement. Cependant, n’avoir que la vue de ces //wait
events// à l’instant présent n’est clairement pas suffisant pour avoir une
bonne idée de ce qu’il se passe sur le serveur. Puisque la plupart des //wait
events// sont pas nature très éphémères, ce dont vous avez besoin est de les
échantilloner à une fréquence élevée. Tenter de faire cet échantillonage avec
un outil externe, même à une seconde d’intervalle, n’est généralement pas
suffisant. C’est là que l’extension
pg_wait_sampling apporte
une solution vraiment brillante. Il s’agit d’une extension écrite par
Alexander Korotkov et Ildus Kurbangaliev. Une
fois activée (il est nécessaire de la configurer dans le
shared_preload_libraries, un redémarrage de l’instance est donc nécessaire),
elle échantillonera en mémoire partagée les //wait events// toutes les 10
ms (par défaut), et aggèrega également les compteurs par type de //wait
event// (wait_event_type), //wait event// et queryid (si
pg_stat_statements est également acctivé). Pour plus de détails sur la
configuration et l’utilisation de cette extension, vous pouvez consulter le
README de
l’extension.
Comme tout le travail est fait en mémoire au moyen d’une extension écrite en C,
c’est très efficace. De plus, l’implémentation est faite avec très peu de
verouillage, le surcoût de cette extension devrait être presque négligable.
J’ai fait quelques tests de performance sur mon pc portable (je n’ai
malheureusement pas de meilleure machine sur laquelle tester) avec un
pgbench en
lecture seule où toutes les données tenaient dans le cache de PostgreSQL
(shared_buffers), avec 8 puis 90 clients, afin d’essayer d’avoir le maximum
de surcoût possible. La moyenne sur 3 tests était d’environ 1% de surcoût,
avec des fluctuations entre chaque test d’environ 0.8%.
Et PoWA ?
Ainsi, grâce à cette extension, nous avons à notre disposition une vue cumulée et extrêmement précise des //wait events//. C’est très bien, mais comme toutes les autres statistiques cumulées dans PostgreSQL, vous devez échantillonner ces compteurs régulièrement si vous voulez pouvoir être capable de savoir ce qu’il s’est passé à un certain moment dans le passé, comme c’est d’ailleurs précisé dans le README de l’extension :
[…] Waits profile. It’s implemented as in-memory hash table where count of samples are accumulated per each process and each wait event (and each query with
pg_stat_statements). This hash table can be reset by user request. Assuming there is a client who periodically dumps profile and resets it, user can have statistics of intensivity of wait events among time.
C’est exactement le but de PoWA: sauvegarder les compteurs statistiques de manière efficace, et les afficher sur une interface graphique.
PoWA 3.2 détecte automatiquement si l’extension pg_wait_sampling est déjà présente ou si vous l’installez ultérieurement, et commencera à collecter ses données, vous donnant une vue vraiment précise des //wait events// dans le temps sur vos bases de données !
Les données sont centralisée dans des tables PoWA classiques,
powa_wait_sampling_history_current pour les 100 dernières collectes (valeur
par défaut de powa.coalesce), et les valeurs plus anciennes sont aggrégées
dans la table powa_wait_sampling_history, avec un historique allant jusqu’à
une période définie par powa.retention. Par exemple, voici une requête
simple affichant les 20 premiers changements survenus au sein des 100 premiers
instantanés :
WITH s AS (
SELECT (record).ts, queryid, event_type, event,
(record).count - lag((record).count)
OVER (PARTITION BY queryid, event_type, event ORDER BY (record).ts)
AS events
FROM powa_wait_sampling_history_current w
JOIN pg_database d ON d.oid = w.dbid
WHERE d.datname = 'bench'
)
SELECT *
FROM s
WHERE events != 0
ORDER BY ts ASC, event DESC
LIMIT 20;
ts | queryid | event_type | event | events
-------------------------------+----------------------+------------+----------------+--------
2018-07-09 10:44:08.037191+02 | -6531859117817823569 | LWLock | pg_qualstats | 1233
2018-07-09 10:44:28.035212+02 | 8851222058009799098 | Lock | tuple | 4
2018-07-09 10:44:28.035212+02 | -6860707137622661878 | Lock | tuple | 149
2018-07-09 10:44:28.035212+02 | 8851222058009799098 | Lock | transactionid | 193
2018-07-09 10:44:28.035212+02 | -6860707137622661878 | Lock | transactionid | 1143
2018-07-09 10:44:28.035212+02 | -6531859117817823569 | LWLock | pg_qualstats | 1
2018-07-09 10:44:28.035212+02 | 8851222058009799098 | LWLock | lock_manager | 2
2018-07-09 10:44:28.035212+02 | -6860707137622661878 | LWLock | lock_manager | 3
2018-07-09 10:44:28.035212+02 | -6860707137622661878 | LWLock | buffer_content | 2
2018-07-09 10:44:48.037205+02 | 8851222058009799098 | Lock | tuple | 14
2018-07-09 10:44:48.037205+02 | -6860707137622661878 | Lock | tuple | 335
2018-07-09 10:44:48.037205+02 | -6860707137622661878 | Lock | transactionid | 2604
2018-07-09 10:44:48.037205+02 | 8851222058009799098 | Lock | transactionid | 384
2018-07-09 10:44:48.037205+02 | -6860707137622661878 | LWLock | lock_manager | 13
2018-07-09 10:44:48.037205+02 | 8851222058009799098 | LWLock | lock_manager | 4
2018-07-09 10:44:48.037205+02 | 8221555873158496753 | IO | DataFileExtend | 1
2018-07-09 10:44:48.037205+02 | -6860707137622661878 | LWLock | buffer_content | 4
2018-07-09 10:45:08.032938+02 | 8851222058009799098 | Lock | tuple | 5
2018-07-09 10:45:08.032938+02 | -6860707137622661878 | Lock | tuple | 312
2018-07-09 10:45:08.032938+02 | -6860707137622661878 | Lock | transactionid | 2586
(20 rows)NOTE: Il y a également une version par base de données de ces valeurs pour
un traitement plus efficace au niveau des basesn dans les tables
powa_wait_sampling_history_current_db et powa_wait_sampling_history_db
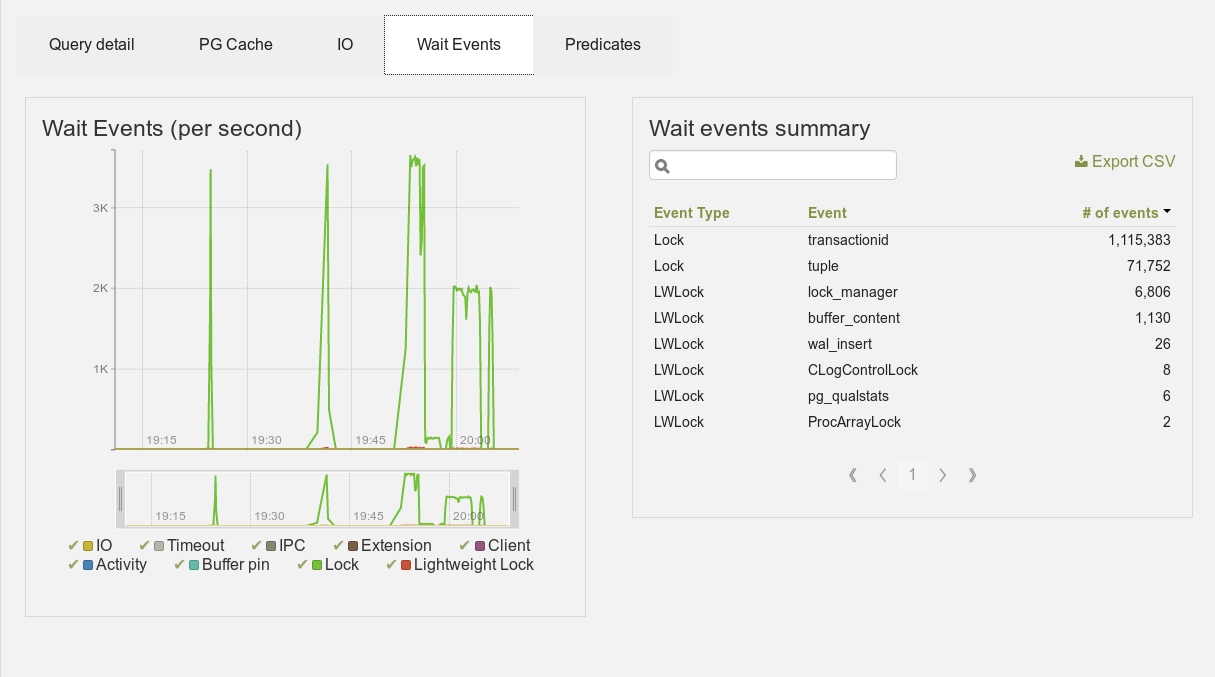
Et ces données sont visibles avec l’interface powa-web. Voici quelques exemples d’affichage des //wait events// tels qu’affichés par PoWA avec un simple pgbench :
Wait events pour l’instance entière
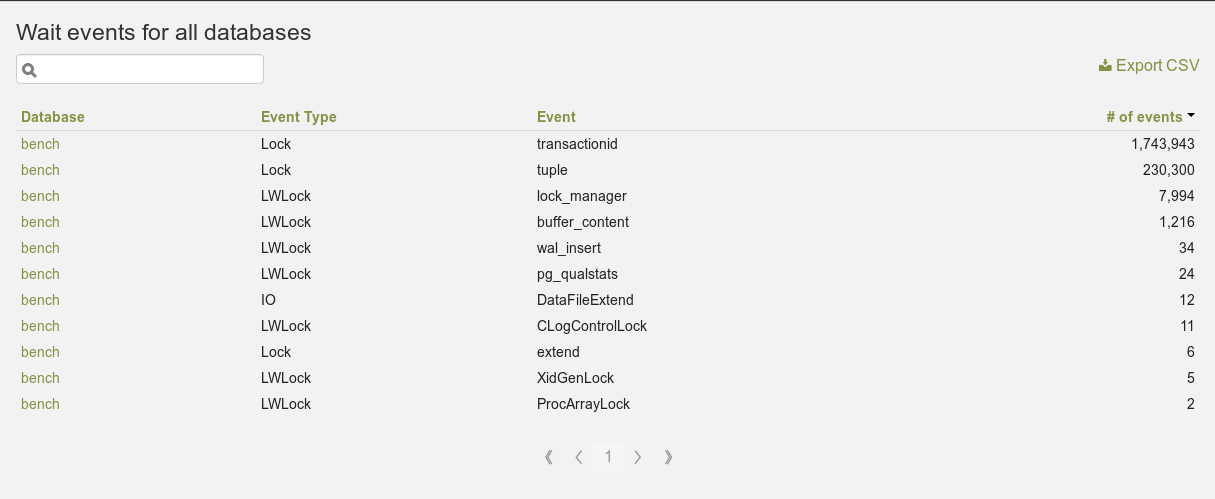
Wait events pour une base de données
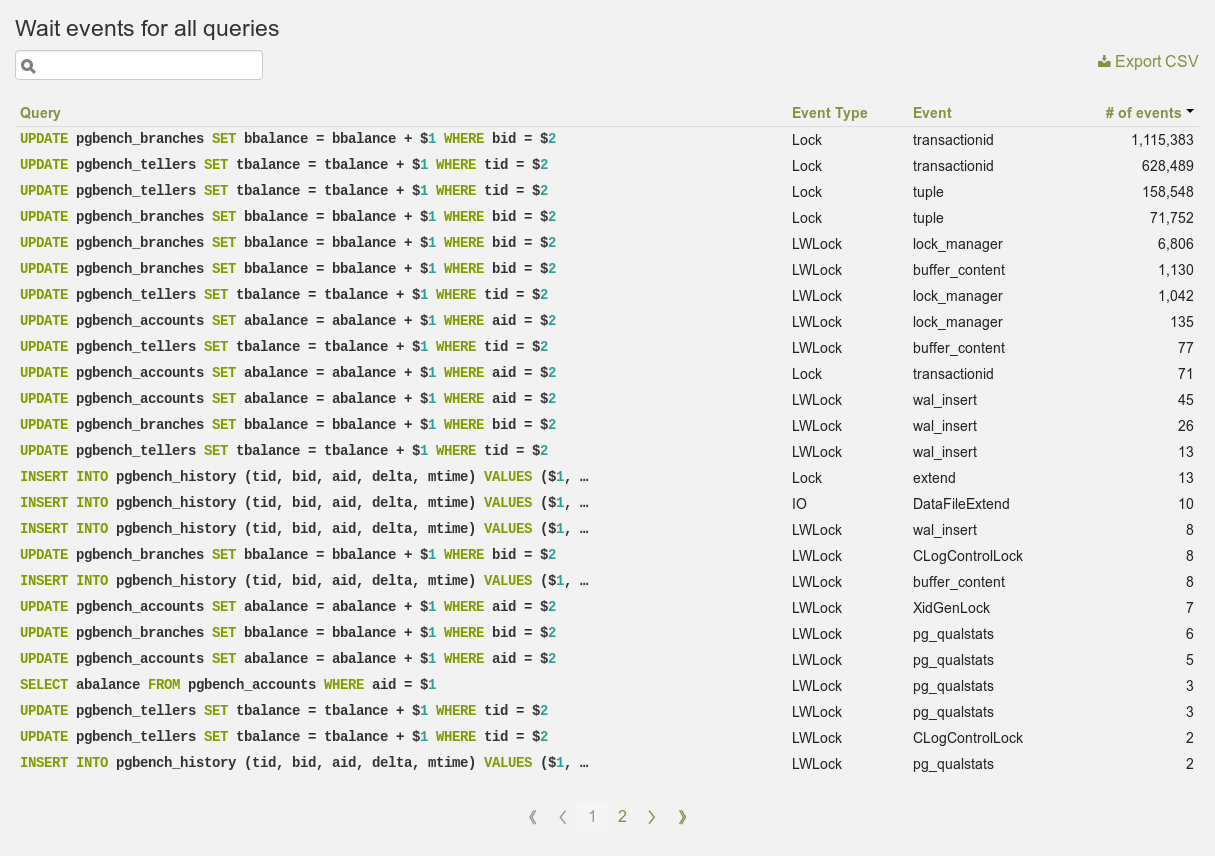
Wait events pour une seule requête
Cette fonctionnalité est disponible depuis la version 3.2 de PoWA. J’espère pouvoir afficher plus de vues de ces données dans le futur, en incluant d’autres graphes, puisque toutes les données sont déjà disponibles en bases. Également, si vous êtes un développeur python ou javascript, les contributions sont toujours bienvenues!