Coming up with good index suggestion can be a complex task. It requires knowledge of both application queries and database specificities. Over the year multiple projects tried to solve this problem, one of which being PoWA with the version 3, with the help of pg_qualstats extension. It can give pretty good index suggestion, but it requires to install and configure PoWA, while some users wanted to only have the global index advisor. In such case and for simplicity, the algorithm used in PoWA is now available in pg_qualstats version 2 without requiring any additional component.
EDIT: The pg_qualstats_index_advisor() function has been changed to return
json rather than jsonb, so that the compatibility with PostgreSQL 9.3
is maintained. The query examples are therefore also modified to use
json_array_elements() rather than jsonb_array_elements().
What is pg_qualstats
A simple way to explain what is pg_qualstats would be to say that it’s like pg_stat_statements working at the predicate level.
The extension will save useful statistics for WHERE and JOIN clauses: which table and column a predicate refers to, number of time the predicate has been used, number of execution of the underlying operator, whether it’s a predicate from an index scan or not, selectivity, constant values used and much more.
You can deduce many things from such information. For instance, if you examine the predicates that contains references to different tables, you can find which tables are joined together, and how selective are those join conditions.
Global suggestion?
As I mentioned, the global index advisor added in pg_qualstats 2 uses the same approach as the one in PoWA, so the explanation here will describe both tools. The only difference is that with PoWA you’ll likely get a better suggestion, as more predicates will be available, and you can also choose for wich time interval you want to detect missing indexes.
The important thing here is that the suggestion is performed globally, considering all interesting predicates at the same time. This approach is different to all other approaches I saw that only consider a single query at a time. I believe that a global approach is better, as it’s possible to reduce the total number of indexes, maximizing multi-column indexes usefulness.
How global suggestion is done
The first step is to gather all predicates that could benefit from a new index. This is easy to get with pg_qualstats, by filtering the predicates coming from sequential scans, executed many time, that filter many rows (both in number of rows and in percentage) you get a perfect list of predicates that likely miss an index (or alternatively the list of poorly written queries in certain cases). For instance, let’s consider an application which uses those 4 predicates:

Next, we build the full set of paths with each AND-ed predicates that contains other, also possibly AND-ed, predicates. Using the same 4 predicates, we would get those paths:
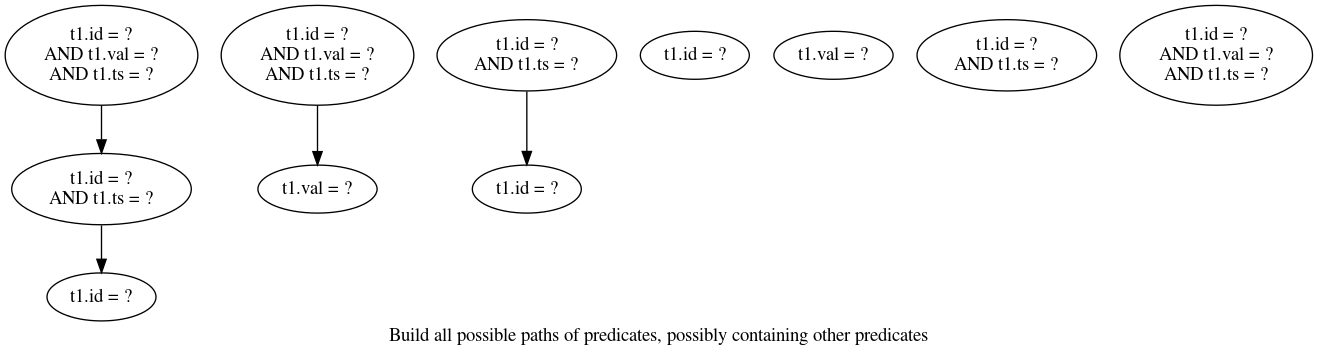
Once all the paths are built, we just need to get the best path to find out the best index to suggest. The scoring is for now done by giving a weight to each node of each path corresponding to the number of simple predicates it contains and summing the weight for each path. This is very simple and allows to prefer a smaller amount of indexes to optimize as many queries as possible. With our simple example, we get:
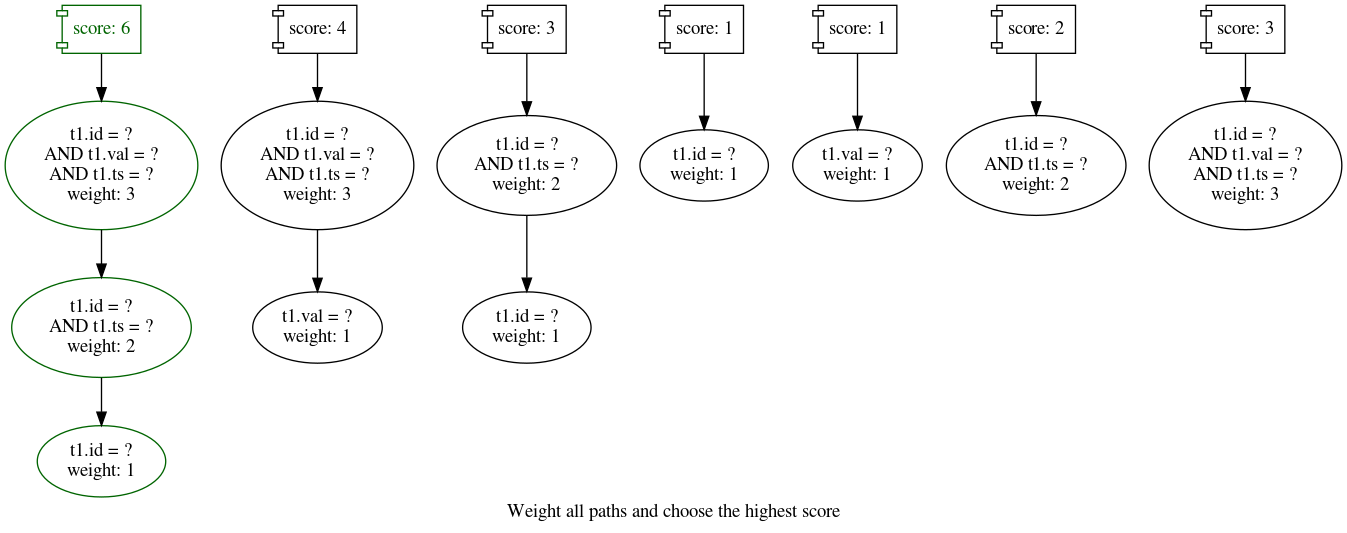
Of course, other scoring approaches could be used to take into account other parameters and give possibly better suggestions. For instance, combining the number of executions or the predicate selectivity. If the read/write ratio for each table is known (this is available using powa-archivist), it would also be possible to adapt the scoring method to limit index suggestions for write-mostly tables. With this algorithm, all of that could be added quite easily.
Once the best path is found, we can generate an index DDL! As the order of the columns can be important, this is done using getting the columns for each node in ascending weight order. In our example, we would generate this index:
CREATE INDEX ON t1 (id, ts, val);Once an index is found, we simply remove the contained predicates for the global list of predicates and start again from scratch until there are no predicate left.
Additional details and caveat
Of course, this is a simplified version of the suggestion algorithm. Some
other informations are required. For instance, the list of predicates is
actually expanded with operator classes and access
method depending
on the column types and operator, to make sure that the suggested indexes are
valid. If multiple index methods are found for a best path, btree will be
chosen in priority.
This brings another consideration: this approach is mostly thought for btree indexes, for which the column order is critical. Some other access methods don’t require a specific column order, and for those it could be possible to get better index suggestions if the column order parameters wasn’t considered.
Another important point is that the operator classes and access method is not hardcoded but retrieved at execution time using the local catalogs. Therefore, you can get different (and possibly better) results if you make sure that optional operator classes are present when using the index advisor. This could be btree_gist or btree_gin extensions, but also other access methods. It’s also possible that some type / operator combination doesn’t have any associated access method recorded in the catalogs. In this case, those predicates are returned separately as a list of unoptimizable predicates, that should be manually analyzed.
Finally, as pg_qualstats isn’t considering expression predicates, this advisor can’t suggest indexes on expression, for instance if you’re using fulltext search.
Usage example
A simple set-returning function is provided, with optional parameters, that returns a json value:
CREATE OR REPLACE FUNCTION pg_qualstats_index_advisor (
min_filter integer DEFAULT 1000,
min_selectivity integer DEFAULT 30,
forbidden_am text[] DEFAULT '{}')
RETURNS jsonThe parameter names are self explanatory:
min_filter: how many tuples should a predicate filter on average to be considered for the global optimization, by default 1000.min_selectivity: how selective should a predicate filter on average to be considered for the global optimization, by default 30%.forbidden_am: list of access methods to ignore. None by default, although for PostgreSQL 9.6 and prior hash indexes will internally be discarded, as those are only safe since version 10.
Using pg_qualstats regression tests, let’s see a simple example:
CREATE TABLE pgqs AS SELECT id, 'a' val FROM generate_series(1, 100) id;
CREATE TABLE adv (id1 integer, id2 integer, id3 integer, val text);
INSERT INTO adv SELECT i, i, i, 'line ' || i from generate_series(1, 1000) i;
SELECT pg_qualstats_reset();
SELECT * FROM adv WHERE id1 < 0;
SELECT count(*) FROM adv WHERE id1 < 500;
SELECT * FROM adv WHERE val = 'meh';
SELECT * FROM adv WHERE id1 = 0 and val = 'meh';
SELECT * FROM adv WHERE id1 = 1 and val = 'meh';
SELECT * FROM adv WHERE id1 = 1 and id2 = 2 AND val = 'meh';
SELECT * FROM adv WHERE id1 = 6 and id2 = 6 AND id3 = 6 AND val = 'meh';
SELECT * FROM adv WHERE val ILIKE 'moh';
SELECT COUNT(*) FROM pgqs WHERE id = 1;And here’s what the function returns:
SELECT v
FROM json_array_elements(
pg_qualstats_index_advisor(min_filter => 50)->'indexes') v
ORDER BY v::text COLLATE "C";
v
---------------------------------------------------------------
"CREATE INDEX ON public.adv USING btree (id1)"
"CREATE INDEX ON public.adv USING btree (val, id1, id2, id3)"
"CREATE INDEX ON public.pgqs USING btree (id)"
(3 rows)
SELECT v
FROM json_array_elements(
pg_qualstats_index_advisor(min_filter => 50)->'unoptimised') v
ORDER BY v::text COLLATE "C";
v
-----------------
"adv.val ~~* ?"
(1 row)The version 2 of pg_qualstats is not released yet, but feel free to test it and report any issue you may find!