Parvenir à une suggestion d’index de qualité peut être une tâche complexe. Cela nécessite à la fois une connaissance des requêtes applicatives et des spécificités de la base de données. Avec le temps de nombreux projets ont essayé de résoudre ce problème, l’un d’entre eux étant PoWA version 3, avec l’aide de pg_qualstats extension. Cet outil donne de plutôt bonnes suggestions d’index, mais il est nécessaire d’installer et configurer PoWA, alors que certains utilisateurs aimeraient n’avoir que la suggestion d’index globale. Pour répondre à ce besoin de simplicité, l’algorithme utilisé dans PoWA est maintenant disponible dans pg_qualstats version 2, sans avoir besoin d’utiliser des composants additionnels.
EDIT: La fonction pg_qualstats_index\_advisor() a été changée pour retourner
du json plutôt que du jsonb, afin de conserver la compatibilité avec PostgreSQL
9.3. Les requêtes d’exemples sont donc également modifiées pour utiliser
json_array_elements() plutôt que jsonb_array_elements().
Qu’est-ce que pg_qualstats
Une manière simple d’expliquer ce qu’est pg_qualstats serait de dire qu’il s’agit d’une extension similaire à pg_stat_statements mais travaillant au niveaux des prédicats.
Cette extension sauvegarde des statistiques utiles pour les clauses WHERE et JOIN : à quelle table et quelle colonne un prédicat fait référénce, le nombre de fois qu’un prédicat a été utilisé, le nombre d’exécutions de l’opérateur sous-jacent, si le prédicat provient d’un parcours d’index ou non, la sélectivité, la valeur des constantes et bien plus encore.
Il est possible de déduire beaucoup de choses depuis ces informations. Par exemple, si vous examinez les prédicats qui contiennent des références à des tables différentes, vous pouvez trouver quelles tables sont jointes ensembles, et à quel point les conditions de jointures sont sélectives.
Suggestion Globale ?
Comment je l’ai mentionné, la suggestion d’index globale ajoutée dans pg_qualstats 2 utilise la même approche que celle de PoWA, ainsi cet article peut servir à décrire le fonctionnement des deux outils. La seule différence est que vous obtiendrez probablement une suggestion de meilleure qualité avec PoWA, puisque plus de prédicats seront disponibles, et que vous pourrez également choisir sur quel intervalle de temps vous souhaitez effectuer une suggestion d’index manquants.
La chose importante à retenir ici est qu’il s’agit d’une suggestion effectuée de manière globale, c’est-à-dire en prenant en compte tous les prédicats intéressant en même temps. Cette approche est différente de toutes les autres dont j’ai connaissance, qui ne prennent en compte qu’une seule requête à la fois. Selon moi, une approche globale est meilleure, car il est possible de réduire le nombre total d’index, en maximisant l’efficacité des index multi-colonnes.
Comment marche la suggestion globale
La première étape consiste à récupérer tous les prédicats qui pourraient bénéficier de nouveaux index. C’est particulièrement facile à obtenir avec pg_qualstats. En filtrant les prédicats venant d’un parcours séquentiel, exécutés de nombreuses fois et qui filtrent de nombreuses lignes (à la fois en nombre et en pourcentage), vous obtenez une liste parfaite de prédicats qui auraient très probablement besoin d’un index (ou alors dans certains cas une liste des requêtes mal écrites). Voyons regardons par exemple le cas d’une applications qui utiliserait ces 4 prédicats:

Ensuite, il faut construire l’ensemble entier des chemins de toutes les prédicats joints par un AND logique, qui contiennent d’autres prédicats, qui peuvent être eux-meme également joints par des AND logiques. En utilisants les même 4 prédicats vus précédemments, nous obtenons ces chemins :
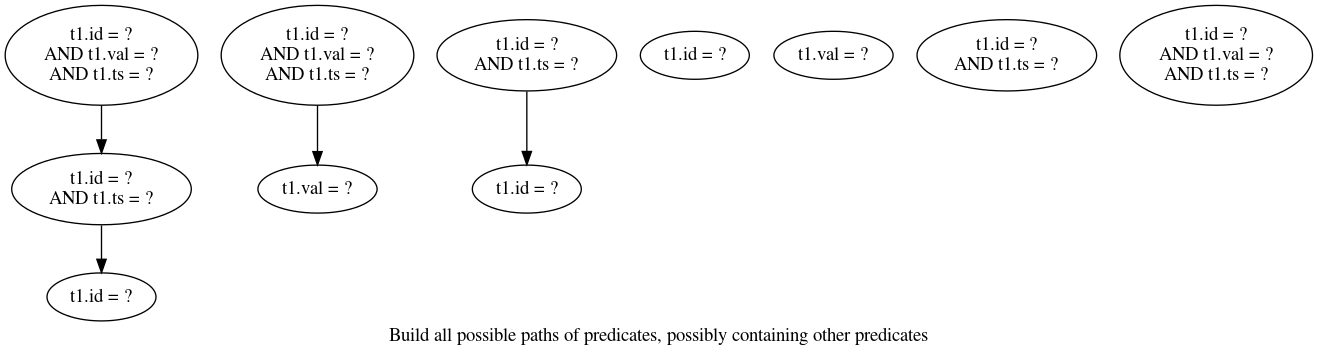
Une fois tous les chemins construits, il suffit d’obtenir le meilleur chemin pour trouver le meilleur index à suggérer. Le classement de ces chemins est pour le moment fait en donnant un poids à chaque nœud de chaque chemin qui correspond au nombre de prédicats simple qu’il contient, et en additionnant le poids pour chaque chemin. C’est une approche très simple, et qui permet de favoriser un nombre minimal d’index qui optimisent le plus de requêtes possible. Avec nos exemple, nous obtenons :
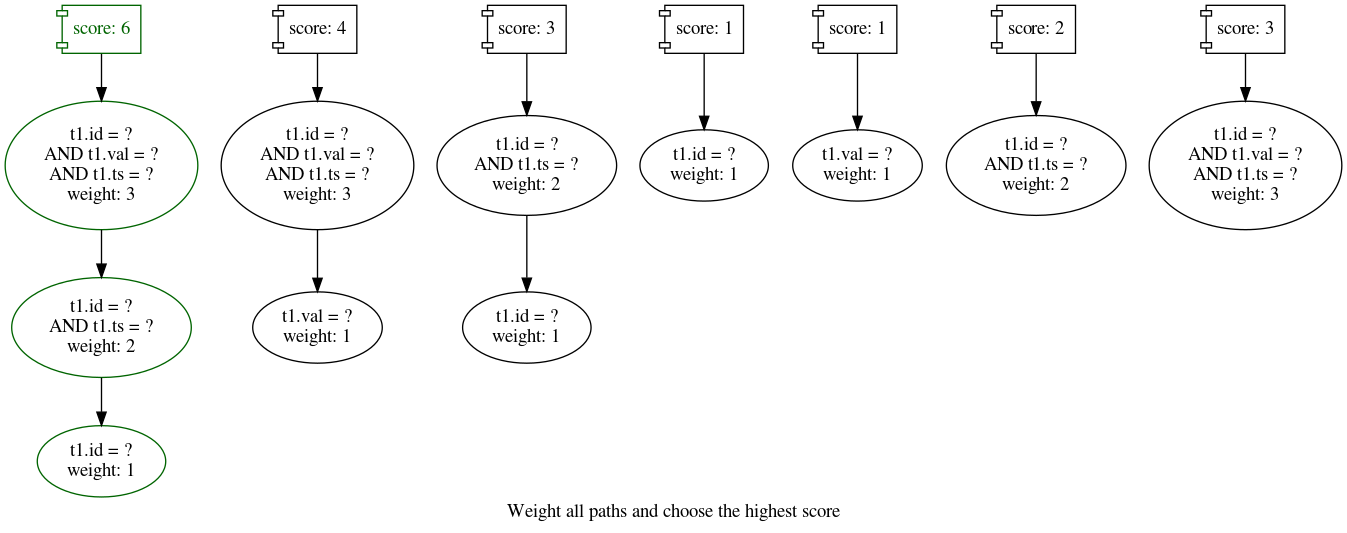
Bien évidemment, d’autres approches de classement pourraient être utilisée pour prendre en compte d’autres paramètres, et potentiellement obtenir une meilleur suggestion. Par exemple, en prenant en compte également le nombre d’exécution ou la sélectivité des prédicats. Si le ratio de lecture/écriture pour chaque table est connu (ce qui est disponible avec l’extension powa-archivist), il serait également possible d’adapter le classement pour limiter la suggestion d’index pour les tables qui ne sont accédées presque exclusivement en écriture. Avec cet algorithme, ces ajustements seraient relativement simples à faire.
Une fois que le meilleur chemin est trouvé, on peut générer l’ordre de création de l’index ! Comme l’ordre des colonnes peut être important, l’ordre est généré en récupérant les colonnes de chaque nœud par poids croissant. Avec notre exemple, l’index suivant est généré :
CREATE INDEX ON t1 (id, ts, val);Une fois que l’index est trouvé, on supprime simplement les prédicats contenus de la liste globale de prédicats et on reprendre de zéro jusqu’à ce qu’il n’y ait plus de prédicats.
Un peu plus de détails et mise en garde
Bien évidemment, il s’agit ici d’une version simplifiée de l’algorithme de
suggestion, car d’autres informations sont nécessaires. Par exemple, la liste
des prédicats est en réalité ajustée avec les classes d’opérateurs et méthode
d’acces en
fonction du type de la colonne et de sont opérateur, afin de s’assurer
d’obtenir des index valides. Si plusieurs méthodes d’accès aux index sont
trouvées pour un même meilleur chemin, btree sera choisi en priorité.
Cela nous amène à un autre détail : cette approche est principalement pensée pour les index btree, pour lesqules l’ordre des colonnes est critiques. D’autres méthodes d’accès ne requièrent pas un ordre spécifique pour les colonnes, et pour ces méthodes d’accès il est possible qu’une suggestion plus optimale soit possible si l’ordre des colonnes n’était pas pris en compte.
Un autre point important est que les classes d’opérateurs et méthodes d’accès ne sont pas gérés en dur mais récupérés à l’exécution en utilisant les catalogues locaux. Par conséquent, vous pouvez obtenir des résultats différents (et potentiellement meilleurs) si vous faites en sorte d’avoir toutes les classes d’opérateur additionelles disponibles quand vous utilisez la suggestion d’index globale. Cela pourrait être les extensions btree_gist et btree_gist, mais également d’autres méthodes d’accès aux index. Il est également possible que certain types / opérateurs n’aient pas de méthode d’accès associée dans les catalogues. Dans ce cas, ces prédicats sont retournées séparément dans une liste de prédicats non optimisables automatiquement, et pour lequel une analyse manuelle est nécessaire.
Enfin, comme pg_qualstats ne traite pas les prédicats composés d’expressions, l’outil ne peut pas suggérer d’index sur des expressions, par exemple en cas d’utilisateur de recherche plein texte.
Exemple d’utilisation
Une simple fonction est fournie, avec des paramètres facultatifs, qui retourne une valeur de type json :
CREATE OR REPLACE FUNCTION pg_qualstats_index_advisor (
min_filter integer DEFAULT 1000,
min_selectivity integer DEFAULT 30,
forbidden_am text[] DEFAULT '{}')
RETURNS jsonLes noms de paramètres sont parlants :
min_filter: combien de lignes le prédicat doit-il filtrer en moyenne pour être pris en compte par la suggestion globale, par défaut 1000 ;min_selectivity: quelle doit être la sélectivité moyenne d’un prédicat pour qu’il soit pris en compte par la suggestion globale, par défaut 30% ;forbidden_am: liste des méthodes d’accès aux index à ignorer. Aucune par défaut, bien que pour les version 9.6 et inférieures les index hash sont ignoré en interne, puisque ceux-ci ne sont sur que depuis la version 10.
Voici un exemple simple, tirés des tests de non régression de pg_qualstats :
CREATE TABLE pgqs AS SELECT id, 'a' val FROM generate_series(1, 100) id;
CREATE TABLE adv (id1 integer, id2 integer, id3 integer, val text);
INSERT INTO adv SELECT i, i, i, 'line ' || i from generate_series(1, 1000) i;
SELECT pg_qualstats_reset();
SELECT * FROM adv WHERE id1 < 0;
SELECT count(*) FROM adv WHERE id1 < 500;
SELECT * FROM adv WHERE val = 'meh';
SELECT * FROM adv WHERE id1 = 0 and val = 'meh';
SELECT * FROM adv WHERE id1 = 1 and val = 'meh';
SELECT * FROM adv WHERE id1 = 1 and id2 = 2 AND val = 'meh';
SELECT * FROM adv WHERE id1 = 6 and id2 = 6 AND id3 = 6 AND val = 'meh';
SELECT * FROM adv WHERE val ILIKE 'moh';
SELECT COUNT(*) FROM pgqs WHERE id = 1;Et voici ce que la fonction retourne :
SELECT v
FROM json_array_elements(
pg_qualstats_index_advisor(min_filter => 50)->'indexes') v
ORDER BY v::text COLLATE "C";
v
---------------------------------------------------------------
"CREATE INDEX ON public.adv USING btree (id1)"
"CREATE INDEX ON public.adv USING btree (val, id1, id2, id3)"
"CREATE INDEX ON public.pgqs USING btree (id)"
(3 rows)
SELECT v
FROM json_array_elements(
pg_qualstats_index_advisor(min_filter => 50)->'unoptimised') v
ORDER BY v::text COLLATE "C";
v
-----------------
"adv.val ~~* ?"
(1 row)La version 2 de pg_qualstats n’est pas encore disponible en version stable, mais n’hésitez pas à la tester et rapporter tout problème que vous pourriez rencontrer !